






本期iProteome为大家带来的是上个月发表在Cell上的一篇文章,本文发现发现的ORFs(开放阅读框)包括能够控制mRNA翻译效率(TE)的上游ORFs(uORFs),以及从长链非编码RNA翻译过来的短ORFs(sORFs)。这就能够在人体组织缺乏全基因组微蛋白目录的情况下,对许多微蛋白重要的生理功能进行揭示。
Highlights
1、核糖体profiling揭示人体组织翻译基本原则
2、揭示截断突变的mRNA下游核糖体翻译情况
3、IncRNAs和cirRNAs产生微蛋白的功能特征
4、微蛋白可参与线粒体和其他细胞中相关过程
Introduction
全基因组翻译体的研究常用的方法是Ribo-seq,该方法可以捕获被核糖体保护的RNA片段的印记。通过这些印记,,核糖体密码子间的移动可以被推导出来,并可用来鉴定活跃的开放阅读框(ORFs)。本文中新发现发现的ORFs包括能够控制mRNA翻译效率(TE)的上游ORFs(uORFs),以及从长链非编码RNA翻译过来的短ORFs(sORFs)。这就能够在人体组织缺乏全基因组微蛋白目录的情况下,对许多微蛋白重要的生理功能进行揭示。
扩张型心肌病(DCM)发病率高达1:250,研究人员阐明了包括DNM和作为对照在内的non-DCM型共80个样本的翻译图谱,结合基因型,转录体和翻译体特征,发现包括titin蛋白截断突变(TTNtv)在内的蛋白质截断突变(PVs),并不能有效终止翻译。此外,研究人员鉴定到具有微蛋白编码功能的169个lncRNAs和40个circRNAs,并进行了体内验证,确定其主要定位于于线粒体上。许多微蛋白是从功能特征性的lncRNA,比如DANCR、TUG1、JPX、翻译过来的,这些微蛋白尚未发现的生物学功能也在本文中进行了探究。这些lncRNAs的大多数在多个组织中都有广泛的存在,研究人员则证明了它们在人类肾脏和肝脏中存在翻译的情况。
Results
人体组织转录及翻译控制的解析
研究人员采用Ribo-seq技术和mRNA-seq对收集到的65例扩张性心肌病(DCM)患者左心室心肌组织和15例正常对照者的左心室心肌组织进行测序(Figure 1A),测序的核糖体印记展示出了预期的分布,主要映射到基因编码序列(CDSs),并显示了活跃的翻译核糖体的3-nt密码子运动特征(Figure 1B),研究人员创建了一个从头开始的转录组程序集对人类心脏中的翻译序列进行编目,并使用RiboTaper自由搜索激活的(Figure 1C)翻译的ORFs。通过将DCM与健康对照组被翻译的RNA分子总体情况进行对比,结合之前的心脏组织蛋白质组学的数据,系统分析了左心室心肌组织中被翻译的ORF和对应的蛋白或多肽的总体信息。共鉴定到了1090个uORF(来自919个基因),20763个典型的的ORF(来自11102个基因),74个dORF(来自62个基因)。还包括了339个sORF(来自于169个lncRNA)(Figure 1E、F)。
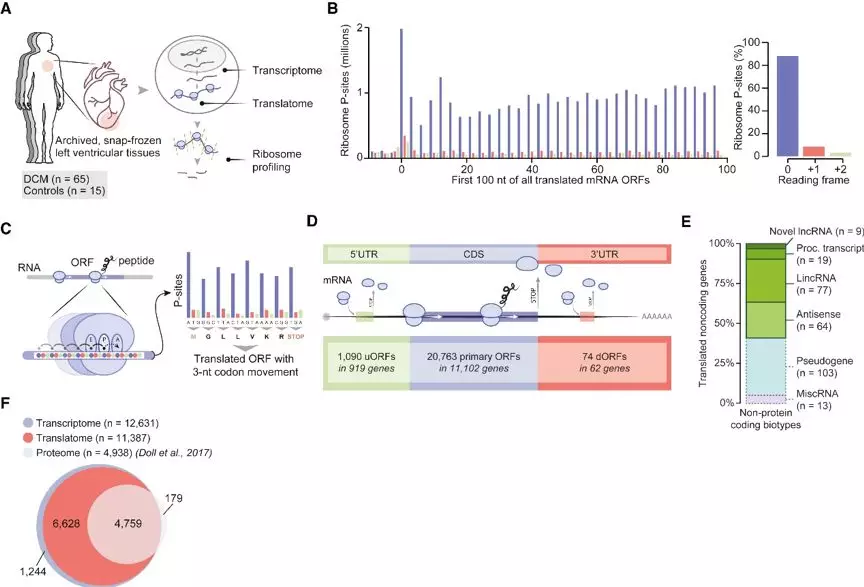
Figure1
随后,研究人员将DCM患者与对照组比较,检测到了2660个带有差异mRNA表达水平的gene和2648在Ribo-seq 数据中差异表达的基因。为了确定特定的翻译调控基因的比例,研究人员使用了一个相互作用模型,解释了转录对基因表达调控的贡献,产生了327个翻译下调基因和474个翻译上调基因。
接下来,研究人员对所有的差异表达基因的翻译水平进行关联,以发现过程特异性表达的协同调控。通共鉴定到了30个协作调控基因,其中的22个富集在不同的细胞过程。PCA分析揭示了细胞外基质(ECM)中存在的特异性翻译上调(FIGURE2B、 2C),可能是心肌损伤和衰竭的典型纤维化反应的表现。此外,研究人员还发现线粒体进程功能的下调是在转录过程中启动的,并在翻译水平上显著增强,反映了衰竭心脏的能量匮乏状态。而mTOR,Sarcomere等相关的通路也受到较明显的翻译效率调控(FIGURE2B、 2C)。
PTVs并不总是截断蛋白翻译
除了常规ORF区,研究人员发现了位于上游区的uORF和下游的dORF也存在着可被翻译的现象。在919个基因中共检测到1090个活化的带有翻译效率下降的翻译的uORF(占所有翻译基因的8%) (Figure 2D)。令人惊讶的是,并没有发现uORFs翻译速率与主要ORFs间的线性联系,只发现了一些总体轻度的正相关(Figure 2E)。分析表明,对于大多数uORF, uORF翻译的频率与主要ORF TE的减少之间没有可检测到的数量依赖关系.然而,DCM的uORF翻译效率总体高于对照组,表明可能存在疾病特异性的uORF翻译调控作用(Figure 2F)。
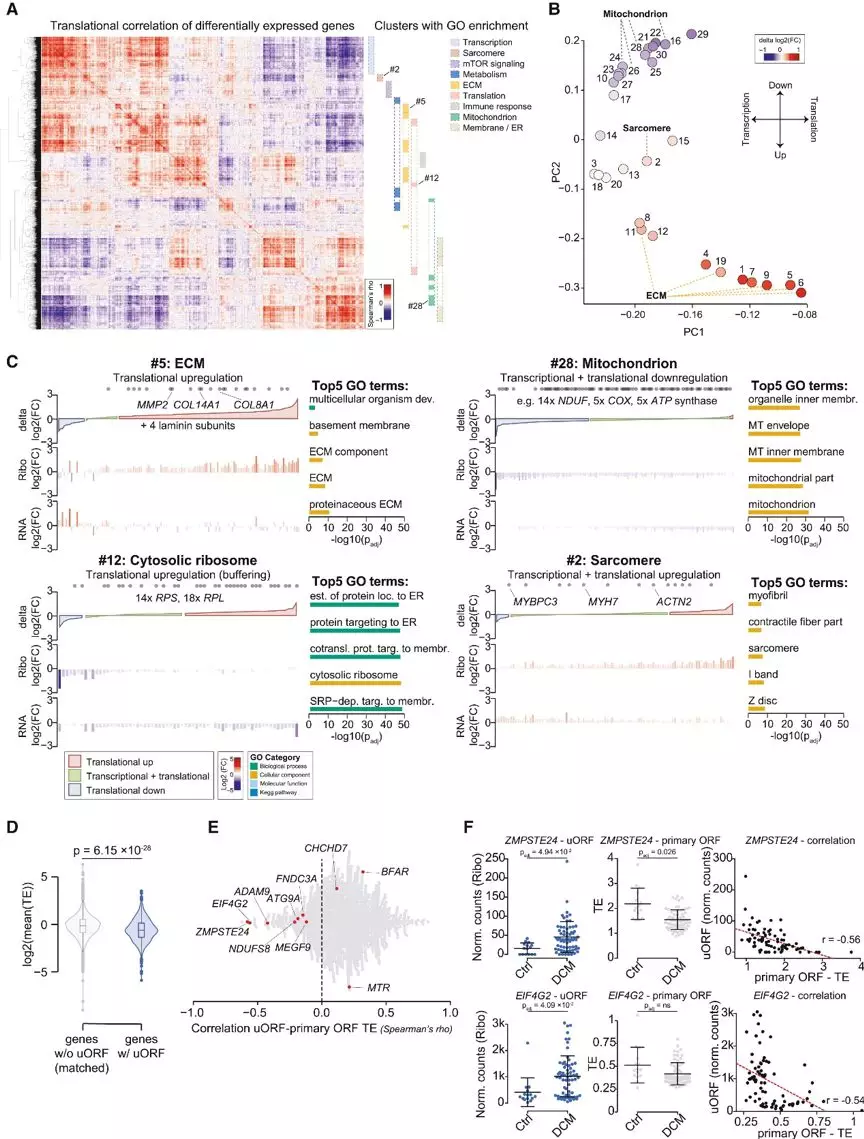
Figure2
PTV可以对蛋白质功能产生显著的影响,但医学上的相关性只建立在一小部分PTVs上,可能是由于基因单倍体充分性、功能冗余或过早停止密码子读取造成的。研究人员鉴定到了346个潜在的ptv: 包括144个无义突变和202个移码突变。随后又对所有检测到的ptv进行了mRNA等位基因比率和RNA-seq覆盖率分析,以用来评估等位基因特异性表达(ASE)和在缺乏无意义介导衰变(NMD)情况下提前停止翻译的能力。只有9.2%的PTVs展示出了显示NMD的杂合SNVs型等位基因失衡(Figures 3A and 3B), 表明许多具有截断突变的等位基因不会发生广泛的NMD。通过比较在ptv前后的核糖体占用率来计算核糖体下降率,以此作为早期成熟前翻译终止的测量方法。在346个PTVs中,只有59个核糖体占用率在引入停止点下游明显低于上游(Figures 3Cand 3D)。因此,对于大多数可以在RNA水平检测到的PTV,翻译要么不能有效终止,要么在PTV下游重新启动,就可能影响这些PTVs的效应。
TTNtvs是导致遗传性DCM最常见的原因。13例DCM患者的TTntvs位于TTN的不同组成的外显子中。虽然与这一结果与之前人类心脏的研究相一致,可与带有TTntvs的两种大鼠模型相比,并未在TTNtv携带者中发现令人信服的NMD证据(Figure 3F)。基于TTNtv下游核糖体足迹所覆盖的杂合SNVs, 发现13个TTNtv载体中只有有4个能够实现提前翻译终止。对于另外的4个TTNtv携带者,翻译似乎持续进行下去或者在TTNtv位点后后重新启动 (Figure 3G),有时甚至等位基因翻译频率接近正常的TTN基因(Figure 3H);另外5个TTNtv携带者也并不展示NMD,表明两个等位基因都进行了翻译。
对于翻译无效终止的原因,无义TTNtvs的下游翻译可能是由于核糖体在框内通过这些密码子而不释放;相对之下,移码的TTNtvs的下游翻译可能是由于在IRESs上的重新激活或者是核糖体移码重新进入主要的TTN ORF造成的。而对携带TtntvZ和TtntvA杂合性移码突变的大鼠模型的心脏蛋白质组分析也验证了这一点(Figure 3I、Figure 3J)。
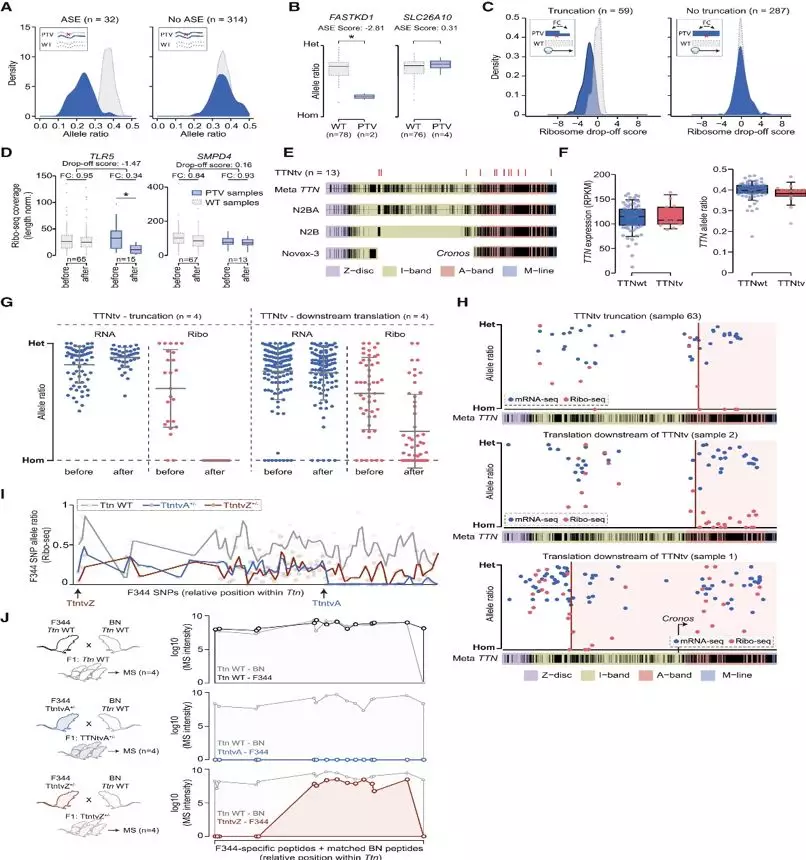
Figure3
综上数据表明了TTN产物广泛的翻译控制。并非所有的TTNtvs都能有效终止翻译,这些翻译模式的发生率因突变和个体而异,这就增加了这些TTNtv对心功能的影响的不同的可能性。
人类心脏、肝脏、肾脏中广泛的非编码RNA翻译
由非编码RNAs翻译来的微蛋白的位置,调控以及潜在功能仍然大量未知。为了搜寻心脏中的微蛋白,研究人员在心脏lncrna中寻找激活翻译的sORF。在783个转录lncrna中,169个(22%)被翻译成潜在的微蛋白,中位长度为49 aa (Figure4A),随后研究人员对这些翻译事件在原代心脏成纤维细胞和诱导多能干细胞来源心肌细胞的翻译体中的翻译进行了独立的验证,已知的心脏微蛋白大部分都被被准确检测到(199个中的190个;95%),包括最近发现的DWORF、SPAR和ALN在内。为了验证所鉴定的sORFs的翻译潜力,研究人员对58个随机选择的可翻译的人类lncRNA的完整转录本进行了体外翻译(IVT)测试,结果有44条都产生了微蛋白产物(Figure 4B)。随后的启动密码子突变阻止了翻译,并导致在预测大小范围内的信号丢失(Figure 4B)。
大多数翻译的lncRNAs的表达并不局限于心脏。研究人员生成了6个人类肝脏和肾脏组织的翻译体来检测这些lncRNAs在其他组织的翻译情况。结果发现,在人类心脏检测到的169个lncrna中,71个(42%)和116个(69%)分别在肝脏和肾脏中表达。其中,56个(肝脏)和87个(肾脏)被积极翻译,所有3个组织中都有50个lncrna被翻译。更加重要的是,对于大多数(85%-91%)lncrna,至少有1个sORF与心脏检测到的sORF相同。通过sORFs.org数据库的对比,在51个翻译lncrna中,有72个sorf之前在人类细胞系中被检测到。数据则证实了这些sorf在人体组织中的翻译的广泛存在并进一步强调了在118个lncrna中之前未检测到的272个sorf的翻译。
随后的小鼠模型试验则表现出了这些lncrna高度的保守性(Figure 4C、4D).
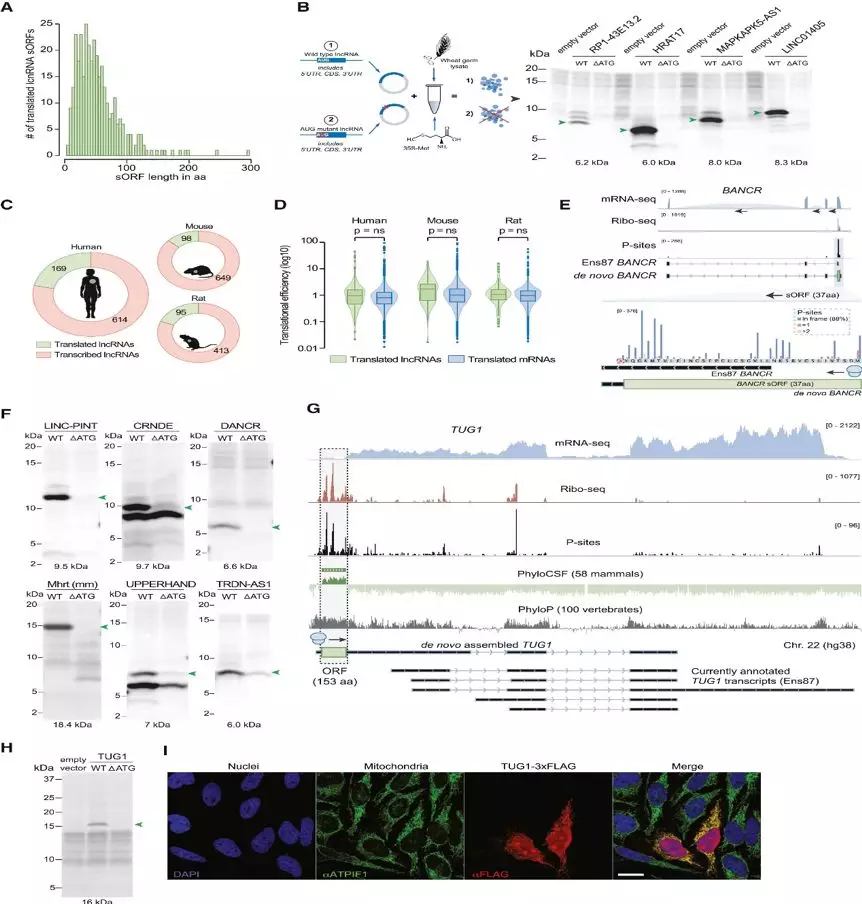
Figure4
通过转录注释(Figure 4E),研究人员鉴定到了包括LINCPINT、JPX、CRNDE 、NEAT1、DANCR 、BANCR and GATA6-AS1在内的多个已知功能的lncRNAs的翻译的sORF(Figure 4F),其中的多条都是和心脏功能相关联的,此外,多数lncRNAs在其他器官中也有发现。
基于上述发现,研究人员研究了具有已知细胞质定位和核糖体关联的功能特征lncRNAs,这些lncrna中并未检测到传统的AUG ORF。但是在lncRNA TUG1发现了一个高度保守的非典型翻译起始密码子的ORF(Figure 4G),随后的体外实验则验证了TUG1的翻译,并表明TUG1坐落于线粒体和细胞核中(Figure 4I)。TUG1在人类和啮齿类动物组织中广泛翻译,其过表达导致基因表达模式的改变。
而对健康和疾病心脏中的翻译的lncRNAs的比较发现,对于所有翻译的lncRNAs,疾病心脏中有34个上调和7个下调,这值得进一步研究。
定位于线粒体的微蛋白及其与线粒体进程的相关性
样本间的基因表达相关性可以作为功能协同调控的一个指标。聚类全基因组表达相关性,研究人员发现以核编码线粒体基因为主的翻译lncRNAs的显著富集,参与氧化磷酸化的基因 (图5A,B)与所选择的翻译lncrna尤其相关.
研究人员汇集了所有的翻译的lncRNA的共调控蛋白编码基因并对其功能特性做了研究。在42个和细胞进程有关的lncRNA中,22个具有线粒体功能(Figure 5C),并选择了其中3个进行了线粒体定位(Figure 5D).对于其余的18个微蛋白,基于其蛋白序列特征和表达共调控模式推测其也坐落于线粒体。

Figure5
线粒体微蛋白PDZRN3-AS1是其中的代表,它是47-aa单通道跨膜螺旋蛋白,研究人员通过三维建模证实了其螺旋结构(Figure 6A). 通过共免疫沉淀、共定位和蛋白酶K消化实验,研究人员发现PDZRN3-AS1与线粒体内膜上的RMND1特异性相互作用(Figures 6B–6E),而OXPHOS亚基的翻译则需要RMND1的协助。
此外,信号肽裂解位点的预测表明,有微蛋白要运输到细胞外发挥功能。
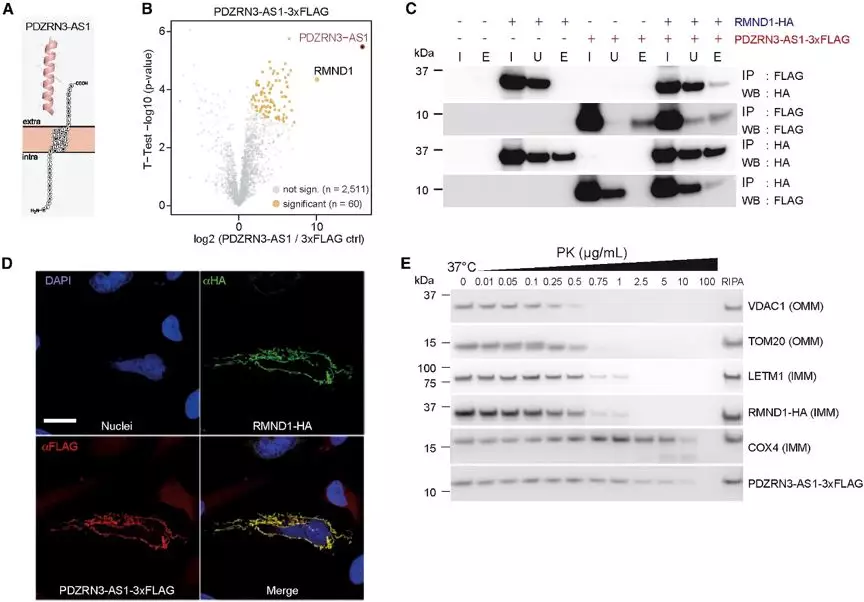
Figure6
人类心脏中circRNAs的翻译
circRNAs是除lncRNAs外的另一种典型的具有翻译潜能的非编码RNA。研究人员总共检测到了2070个新的lncRNAs。核糖体关联的数据表明40个环状rna的蛋白质翻译由可能39个基因产生(Figure 7A) 这些环状rna主要存在于CircBase中(Figure 7B),并显示对RNase R的强抗性。通过分析被核糖体捕获的circRNA接口序列得到的可翻译的circRNA信息,确保了在阅读circRNA backsplice junctions时Ribo-seq的队列特定性(Figure 7C). 这40个circRNA中有6个circRNA的翻译产物在早期的蛋白质组学研究中有对应的质谱线索。其中既有我们熟知的明星分子,包括CDR1as等等,也有全新的发现,比如circCFLAR,circSLC8A1,circMYBPC3和circRYR2是首次发现的心肌中可被翻译的circRNA分子(Figure 7E、F)。
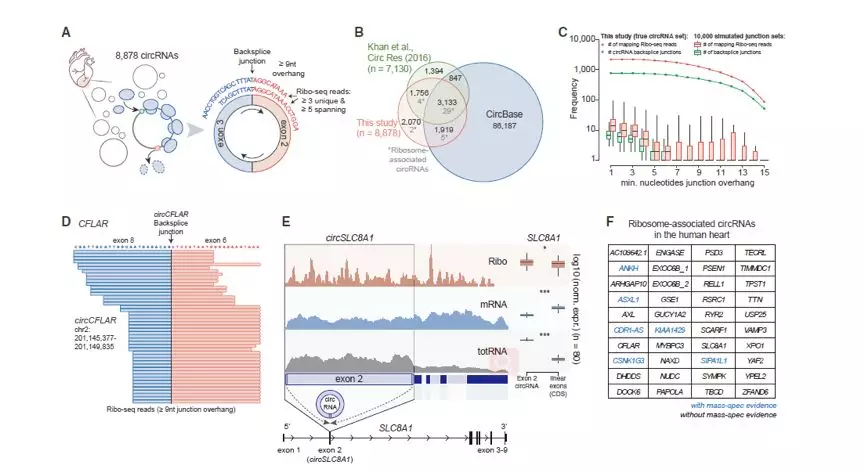
Figure7
Summary
研究人员通过对80个人类心脏的翻译体进行分析,鉴定到了许多全新的翻译事件并对翻译调控效应进行了量化:展示出了广泛的心脏基因表达翻译控制,可能的疾病诱发性的蛋白截断突变的下游翻译很常见,体现出了翻译终止的低效性;鉴定到了几百个全新的来自于lncRNAs和circRNAs的微蛋白,并进行了体内验证,这些微蛋白的翻译并不局限于心脏,主要存在于人类肾脏和肝脏的翻译体中。研究人员将这些微蛋白与多种细胞过程和细胞间隔相联系,发现许多定位于核糖体,并于氧化磷酸化的进程机密联系。更加重要的是,几十个微蛋白来自于特征鲜明的非编码RNAs,这可能揭示了一些之前未被注意到的到的生物机理。

此文的原始文章名称叫什么?
原文:DOI.org/10.1016/j.cell.2019.05.010